New architecture for a new catalogue
Once the Library made the decision to build a new catalogue, our back-end development team knew they were faced with a huge challenge. As part of our ‘going headless’ approach, and to meet the lofty ambitions required of our new unified user interface, we had to go back to the drawing board when it came to designing the underlying technical architecture that would support these goals. What we came up with was a single coherent data model accessible through an API (Application Programming Interface) layer, which was backed by cloud based scalable infrastructure.
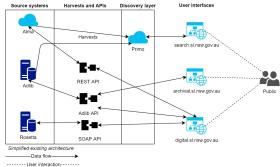
A look at our existing architecture before we embarked on the new catalogue project:
A new data model
Almost all aspects of Library business operations, from acquisitions to preservation and reader access relies upon data to function smoothly. It should be no surprise then, that data was a central area of focus when building a new catalogue experience. Historically, the State Library’s catalogue data has been split into independent data silos. We have a silo for our published material (books, newspapers, etc), a silo for our archival material (manuscripts, paintings, photographs, etc) and a silo for our digital assets (image, audio and media files). Although this has been a logical approach for staff to manage behind the scenes, the separation didn’t make sense for most of our readers, who just want to access our collections without needing to know where they ‘live’. It also meant each of the separate source systems had its own user interface that wasn't always consistent with the others, and this often created a confusing user experience.
We decided the best solution was to integrate the sources at the data level - published, archival and digital data all living together harmoniously. This would provide us with the foundation on which to build an API for a unified user interface application.
Data storage and pipeline
A data model is a good start, but without a concrete implementation it’s little more than a pretty diagram. To make this happen we investigated a range of options and landed on two core technologies. Because search functionality is central to any library catalogue, we chose the feature rich and scalable open source search solution Elasticsearch built on Apache Lucene. This is the engine behind all the searches conducted on our new catalogue. Initially we designed the architecture with Elasticsearch as the single data store, but it quickly became clear that we would benefit from a traditional relational database to complement Elasticsearch. We decided on PostgreSQL, a powerful open source relational database system, which we use to support basic CRUD operations and ensure relational integrity of our data.
The next challenge was how to get the data into our data storage. The first step was to map all source data fields to the new data model. This involved developers and cataloguers sitting down together and mapping each field, from each data source, one at a time. We documented properties such as source field name, destination field name, data type and normalisation procedures. After mapping more than 200 data fields over several months, we had a massive spreadsheet that served as the blueprint for our ingestion pipelines.
The data ingestion implementation uses a combination of OAI-PMH and various source system APIs to harvest data. As our cataloguers are continually creating and updating records, it's not enough to take a single copy of data from our systems; rather we needed to be able to support incremental daily harvesting that would capture regular changes to any of our source data. Using OAI-PMH we can easily find out what records have been created or changed over a particular period and subsequent API calls are used to pull in the full source system records.
Cloud based infrastructure
One of the main requirements given to the back-end team was to build a scalable, highly available system. After extensive investigation and testing we decided that Amazon Web Services was most suitable for our infrastructure. Amazon provide a wide range of cloud infrastructure services, from traditional virtual machines to serverless compute platforms.
To benefit most from cloud-based infrastructure we took the plunge into the serverless world and built our architecture on top of AWS Lambda. This allows us to run our code without having to worry about provisioning or managing servers. AWS Lambda scales automatically and you only pay when code runs, in contrast to more traditional compute infrastructure where your servers run 24/7 and you pay for every minute.
For our Elasticsearch and PostgreSQL databases we again considered traditional virtual servers in the form of AWS EC2. However, with the cloud centric approach in mind, we decided to use Amazon RDS for our PostgreSQL databases and Amazon Elasticsearch as a service for our Elasticsearch instances. Again, this means not having to worry about managing servers, and each of these services allows us to scale up easily to meet increased demand when required.
API layer
Once we had all our data organised into a single coherent data model, the next step was providing access to it. Our headless approach for building our user facing application required us to build an API. We first considered rolling our own custom lightweight solution but eventually determined that we would benefit more from the many features provided by existing API management software. We investigated different options and settled on Google’s Apigee. In addition to allowing us to define and deploy API endpoints, Apigee helps us to monitor our API usage, manage keys, track and debug request/response cycles and cache responses to improve performance.
Apigee is a solid platform on which to build an API, but in order to do this we first had to design what the API would look like and how it would function. Our API design is driven by the requirements of our readers. If readers want to access certain data when searching or browsing our collections, our API design must ensure that the data is available in all the places readers expect to find it. Our API design must be evolving and flexible. As new front-end features are developed or existing features modified, the API must be able to support these changes. In this sense, the API acts as a contract between our back-end and front-end development teams, clearly stipulating what is required and what is delivered. In order to document this contract, we follow the OpenAPI specification and use ReDoc to generate the html documentation.
Our improved, cohesive back-end architecture model that supports our new catalogue:
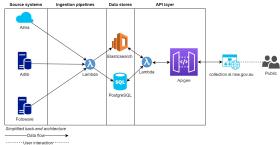
Once the architecture and API were designed and in place we could kick off the process of ingesting our digital files through the new data pipelines. This ingestion has taken months of work, and we'll go into more detail in a later post. To date we have ingested more than 4.3 million files and made them available to the public via our new catalogue.
In future posts we will also break down our data model, architecture and API layer in more detail. For now, we hope you enjoy using our new catalogue with a newfound appreciation for the work that has gone on 'under the hood' to make this improved user experience possible.
Peter Brotherton, Robertus Johansyah & Rahul Singh
Back-end development team